This section covers most of information about managed objects. However, you need to get acquainted with the IDL and some other topics more properly to be able to write a managed class in practice. Chapter 13, Creating Managed Class shows in detail and using a practical example how to create a managed class step-by-step. However, before reading it, you should already have read all the chapters between this and that one.
![[Note]](images/note.png) | Note |
|---|---|
Note again that the managed objects are properties as well (Massiv::Core::Object inherits Massiv::Core::Property). They can act not only as property hierarchies roots, but they can also be owned by another properties. | |
| Note |
|---|---|
Each managed object is associated with two special objects. The metaobject holds the meta-information about the relevant class (its base class, method list, ...) and enables introspection that is useful for the Core to instantiate managed objects, etc. (but can be used by the application as well). The object factory is responsible for objects and replicas instantiation. | |
Let's first look at an overview about what steps you need to accomplish when implementing a managed class. A step-by-step example is available in Chapter 13, Creating Managed Class.
Implement the class in C++ according to the rules mentioned below in Section 4.3.1, “Implementation”.
Write an IDL description for the class. In particular the description contains information about the inheritance hierarchy, class methods (together with specification which parameters are input or output), owned properties, class attributes (such as whether the class is permitted to be archived, etc.) The IDL preprocessor generates source code for the relevant metaobject, object factory and several more auxiliary classes.
For more information about the IDL Chapter 9, Introduction to IDL is a good starting point. See also Chapter 12, Metaobjects for more information about metaobjects.
Add an entry into the relevant idl.list file. Each entry specifies one idl file involved in an application and is needed to make the preprocessor to take the file into account.
To get more information about the idl.list see Section D.2, “The idl.list File”.
As already mentioned, managed objects technically are instances of any class derived (directly or indirectly) from the Massiv::Core::Object base class that moreover conforms to some implementation restrictions and limitations. All the limitations are described in the following list:
Inheritance
Firstly, all managed classes should use only the public inheritance.
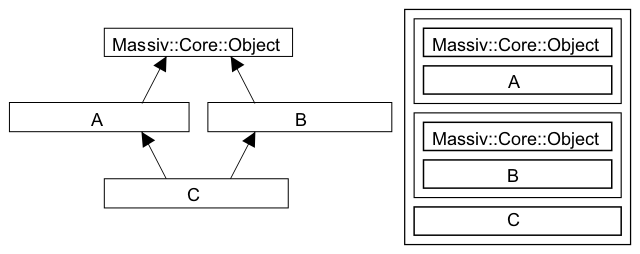
If you want to use the multiple inheritance for your managed objects, it is an important requirement that the objects must inherit Massiv::Core::Object exactly once (i.e. only one instance of the Massiv::Core::Object component is permitted). For example the situation in the following picture is invalid:
The left half of the figure represents the inheritance hierarchy, whereas the right one shows the component structure of the result class C.
Classes A and B both inherit Massiv::Core::Object. The class C is derived from both A and B using the multiple inheritance.
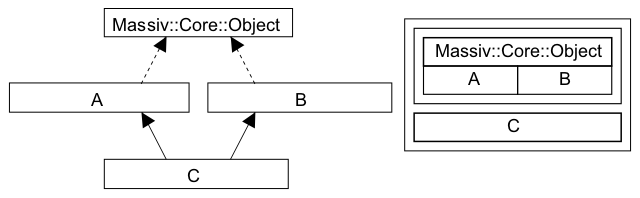
To avoid multiple instances of the Massiv::Core::Object in the managed object, it is strongly recommended either to use virtual base classes or to avoid multiple inheritance at all. Example:
class A : virtual public Massiv::Core::Object { ... }; class B : virtual public Massiv::Core::Object { ... }; class C : public A, B { ... };The class C structure is shown in the following figure:
The dashed lines stand for the virtual inheritance (i.e. the base class marked virtual).
Construction
Because managed objects can be generally constructed multiple times, the application programmer should not write his own user-defined constructors. Instead, the Core takes over the responsibility for managed objects instantiation and initialization (the relevant code is generated on the IDL basis).
Instead of constructors, the programmer must supply the initialize() pseudoconstructor that will be called by the Core only once after the object's first instantiation. The pseudoconstructor must properly initialize the object itself, its base classes (typically by calling the inherited initialize() methods) and member objects (the similar way).
initialize() is not being called automatically by object factories. You must either call it manually or use special templates described below (see Section 4.3.2, “Instantiation and Finalization”).
Note Although they are also managed object descendants, value types and throwables are exception from this rule, see below. This fact adds some implementation requirements, but simplifies their usage.
Access specifiers of methods
All methods defined within managed objects that can be called using RPC (i.e. methods that are specified in the IDL) must be declared public.
Overriding Massiv::Core::Object's methods
Some of the methods in Massiv::Core::Object are virtual. However, in derived managed objects, the programmer should override only those that are explicitly tagged as virtual in the src/core/object/object.h file. Other methods, even those that are declared virtual in some of the Massiv::Core::Object's ancestor classes, may not be overriden.
MASSIV_OBJECT macro
Unlike methods, properties owned by managed objects can be private or protected as well as public. To enable the Core to initialize and handle a managed object properly, the relevant metaobject and object factory must be allowed to access all properties contained in the object. This can be achieved by declaring metaobject and object factory as friend classes. You can use the MASSIV_OBJECT macro to do this for you.
class MyManagedClass : public Massiv::Core::Object { MASSIV_OBJECT( MyManagedClass ); ... }
Because managed objects has to be initialized by the Core, you cannot instantiate them using the standard C++ new operator. Instead, there exist some special templates the application programmer is supposed to use.
The following list enumerates possible ways how to instantiate managed objects:
CreateObject macro
Creates a new class instance using the relevant object factory, does all the basic initialization and calls the user-defined initialize() pseudoconstructor.
ObjectOnStack template
Use ObjectOnStack when you want to create an object on the stack. It is a template that encapsulates the "target" object on the stack. You need to use it to enable the Core to take control over the proper object initialization process. It is used as a handle to the stored object that can be accessed either by a defined conversion or explicitly using the dereference() method or the operator->().
ObjectOnStack also calls the initialize() pseudoconstructor automatically. All parameters passed to the ObjectOnStack will be passed to initialize(). Note that output parameters are not allowed.
Note You cannot reference objects created by ObjectOnStack by ObjectPointer instances.
Note You don't need to use the ObjectOnStack template for the value types, because they can be constructed and initialized using the standard constructors.
The following example shows how to create an object on the stack. Let's suppose we work with a managed class Foo and a value type ValueTypeFoo, both having a method foo:
{ ObjectOnStack< MyManagedClass > my_object( ... ); MyValueTypeClass my_value_type_object( ... );
MyValueTypeClass my_value_type_object( ... );  my_object->foo();
my_object->foo();  ( ( MyManagedClass & ) my_object ).foo();
( ( MyManagedClass & ) my_object ).foo();  my_value_type_object.foo();
my_value_type_object.foo();  }
} 
Instantiation of managed object with pointer semantics on the stack. initialize() will be called automatically.
The ellipsis stands for a list of parameters that would be passed to the MyManagedClass's initialize() method.
Instantiation of value type on the stack. There is no need to call initialize(), because standard constructors are sufficient. It can be handled the same way as unmanaged objects.
Invocation of the foo method on the object created using ObjectOnStack.
This is another way how to invocate the method on the managed object on the stack. As you can see, this is much more cumbersome than the previous one and thus we do not recommend it. However this line should demonstrate that the retyping operator or the ObjectOnStack wrapper works.
Unlike in the previous case, here the value type doesn't have any "wrapper" and thus neither dereferencing using the operator->() nor retyping is needed.
At the end of scope both my_object and my_value_type_object will be destroyed.
ObjectFactory
Of course you can create object using the relevant object factory. However, this isn't a way you are supposed to take. It is more difficult and you would have to call initialize() by hand.
Managed object that are not created on the stack will be destructed automatically by the garbage collector (see Section 5.4, “Garbage Collector” for more information). The on-the-stack objects are destroyed according to the standard scoping rules. Because they cannot be referenced by managed objects, there cannot remain any invalid pointer to the object after it is destroyed.
It is strictly banned to use native C++ pointers or references to reference managed objects. The reason should be already obvious: the Core can for example migrate or swap the object out anytime. The native pointer would thus become invalid and its dereferencing would cause an application crash.
A safe way to reference managed object is to use ObjectPointer. Pointers won't be discussed in this chapter, see Chapter 5, Pointers instead.
Value types are descendants of the Massiv::Core::ValueType class. Use value types for managed objects that can be handled as a value, i.e. they don't need some special initialization, copying and handling from the Core. Their purpose is to enable application to implement property-like structures outside the Core.
Value types advantages and drawbacks are summarized in the following list:
It is more simple to create them on the stack.
They can be used as arguments or result types of RPC methods.
They can be used in place of properties.
They can be instantiated the same way as properties in most of places.
They should not be created as a stand-alone objects (i.e. on the heap).
The most significant difference of an implementation of a value object from an implementation of a "standard" managed object is that the former doesn't have the initialize() pseudoconstructor. Thus, they cannot be instantiated using the CreateObject or ObjectOnStack constructs. Instead, you should handle them as values (which means, besides others, that you also cannot use C++ operator new for their instantiation).
The following list summarizes implementation restrictions you must respect while writing a value type class:
Construction
Unlike for general managed objects, you are supposed to write your user-defined constructors for value types (even to override the default constructor). You should use general managed object instead in case that the fact the object can be instantiated multiple times matters.
Each constructor must call initialize_object() as its first command. It enables Core to do some initialization of its own.
Default constructors are expected to call default_constructed() to indicate that the object has been created the default way.
![[Warning]](images/warning.png)
Warning Constructors of value types must not interact with the simulation.
Copy constructor
Each value type must have a copy constuctor implemented. It must also call the inherited copy constructor.
Destruction
Value types cannot have user-defined destructors.
RPC methods parameters
Value types that can be used as method parameters in RPC calls cannot contain strong pointers (pointers that always references local object, see Chapter 5, Pointers) within. The reason is that the process of transmitting them over the network is simplified.
Embedding
Value types can embed each other in the natural way.
Property restrictions
Value types are properties, thus all restrictions of properties apply for them (unless stated otherwise).
The following code listing shows a complete example of a value type implementation:
| | initialize_object() must be the first command in each constructor. |
| | The default_constructed() indicates that the object has been constructed the default way. |
| | Of course value objects can inherit each other. The same rules as for managed objects apply, i.e. inheritance must be public and should be virtual if multiple inheritance is used. |
Value types can be handled as values:
{
MyPair pair; |
| | Value types can be instantiated as properties. No CreateObject or ObjectOnStack constructs. |
| | They can be handled as values - inserted into containers, etc. |
"Throwables" are managed objects (in fact, they are value objects) that can be thrown as exceptions. The Core is able to propagate them to the caller nodes during remote calls. In fact they are one purpose objects with value semantics.
You can throw a throwable object using the standard throw keyword. However, you can also create the object by hand and throw it using the raise() method (it throws a copy of the throwable object).
Note that not all exceptions used by the Massiv are managed objects. The Core itself implements its own hierarchy with base class Massiv::Core::Exception inherited from std::exception (the generic exception defined in the STL library). The Massiv::Core::Throwable class is also included into this hierarchy - it adds the managed objects' functionality to the exception interface of Massiv::Core::Exception.
| Note |
|---|---|
The exceptions implemented by the Massiv that are not Throwable descendants should be neither thrown nor catched by the application code (the Core should never let its internal exception leak into the application code). If a non-managed exception is thrown by the Core on the target node during the RPC call, the Core itself will catch it and remap (wrap) into the Massiv::Core::Lib::CoreException that is inherited directly from Massiv::Core::Throwable. It enables even the internal Core exceptions to be transmitted back to the caller nodes. | |
The only exceptions the application code should work with are Massiv::Core::Lib::RuntimeException descendants. Feel free to define as many these exceptions as you need, but don't forget that the managed exceptions need their IDL description.
| Note |
|---|---|
The Massiv exceptions doesn't make (nor intend to make) the Massiv "application-programmer-resistant". They should be used for notification about extern failures that can't be simply influenced by the programmer. For example sending wrong parameters (wrong format, type, ...) using the RPC won't probably throw an exception but the application will crash. It is the programmer's responsibility to make sure he uses the Massiv Core correctly (use the debug build of the Core to force more extensive tests). | |
| Note |
|---|---|
Managed exceptions that won't be catched at all won't stop the simulation; they only will be processed by the logger. | |
An application programmer can schedule an object for migration (i.e. transmitting the object to another node, see Chapter 6, Migration). The Core will inform the object about a result of the operation by calling a defined callback (a virtual method that can be overriden in the specific managed object).
The main methods that can be used to make an object migrate are:
| Method | Notes |
|---|---|
| EventHandle schedule_to( ... ) | Enables to schedule the object migration to a specific time, The migration is addressed by another object (referenced by a weak pointer). The event is scheduled public, i.e. it can be cancelled anytime using the handle returned from the method. |
| void migrate_to( ... ) | This method does the same as the previous one, but doesn't return any handle. Thus, the event is scheduled private and cannot be cancelled. |
| void deliver_asap_to( ... ) | The main difference from migrate_to() is that if the target object is local, the delivery will be done immediately. Note that the informative callback will already have been performed when deliver_asap_to returns. However, it is a good idea not to make any assumptions about this order. |
Let's now have a look at the callbacks that are used by the Core to inform the object about the migration result. Note that the callback will be always called after the migration, i.e. potentially on a different node than where the migration was requested.
| Callback | Notes |
|---|---|
| void delivered_to( ... ) | Called upon the successful object delivery. The system passes the destination object (guaranteed to be local) and the delivery time as parameters. |
| void delivery_failed( ... ) | Called when the object migration has failed. The system passes the failure reason as a parameter. |
To get a complete picture, let's describe one more managed object callback. This one has just a little in common with migration:
| Callback | Notes |
|---|---|
| void object_updated( ... ) | Notifies object about its state change [a]. |
[a] Possible change values that can be passed to object_updated() are:
| |
Typically nodes running a Massiv application are divided into servers and clients. Servers collaborate on the simulation, whereas clients are responsible for presentation of the simulation state to users (players). Both client and server nodes work with managed objects, but, however, they don't need the same set of them. Servers work with object that are needed for the simulation, clients with presentation objects and shared objects are used for communication between them.
The Massiv offers a mechanism that enables to link each type of node with code of only those objects that it really needs for its work. It is advantageous both for efficiency (it cuts down the size of the executable files) and safety (it prevents client from illegaly modifying classes that are able to influence the simulation).
This mechanism is called class kinds. The Massiv distinguishes among three class kinds: KIND_SERVER, KIND_CLIENT and KIND_SHARED. Only the last kind is supported explicitly by the Core; the others are defined in src/core/object/object.idl. The kind for any managed class can be specified inside the relevant IDL file (see Example 10.1, “A class description in the IDL” for example).
Managed classes of the same class kind are grouped into a single compilation/linkage unit. Each node supports its specific set of class kinds, i.e. it has the relevant meta-data (needed to instantiate and manage the classes) and the code of the classes.
The class of kind that is not supported by some node is called alien class in respect to that node.
The following list shows the rules that you need to respect while implementing managed classes:
A managed object of any kind can be inherited from another object of KIND_SHARED.
A managed object inherited from another object of another class kind than KIND_SHARED must be of the same class kind as its ancestor. For example, you cannot create managed object of KIND_SHARED by deriving it from KIND_SERVER.
The following list summarizes rules that are obligatory to the Massiv build system and the Core:
KIND_SHARED classes code will be linked with code of all types of nodes.
KIND_SERVER classes code will be linked with code of only server nodes.
KIND_CLIENT classes code will be linked with code of only client nodes.
A node can't instantiate or otherwise use objects that are alien in respect to it. It is not surprising, because we already know the node doesn't have the relevant code and meta-information available. As a consequence, KIND_SERVER objects aren't allowed to migrate or to be replicated to client nodes and vice versa. This ensures for example that clients can never modify server objects.
Despite the previous paragraph, a node can reference alien objects using the remote pointers. It enables calling methods using the RPC (see Chapter 8, Remote Procedure Call) even on "aliens".